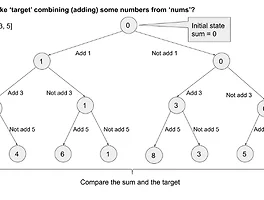
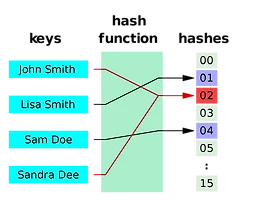
ALGORITHM/Algorithm 설명 (13) 썸네일형 리스트형 [알고리즘] DFS (Depth First Search) DFS (Depth First Search) 그래프를 전체 탐색하는 깊이 우선 탐색 DFS는 탐색을 시작한 시작점부터 해당 부분을 완벽하게 탐색하고 다음으로 넘어가는 방식이다. 아래 그림을 보면 좀더 빠르게 이해할 수 있다. 위 그림처럼 한개의 분기에 대해 모든 탐색이 완료되면 다음 분기로 넘어가고, 완벽하게 탐색한 후에 다음 분기로 넘어가는 흐름을 띄고 있다. 이는 스택, 재귀호출 방식으로 구현할 수 있다. 일반적으로 재귀호출을 사용하였을때 구현하기 편해 자주 사용하지만, 스택오버플로우가 발생할 수 있기 때문에 잘 구현해야 한다 (노드 방문시 방문여부를 검사하면서 진행해야 무한반복에 빠지지 않을 수 있다). 장점 한 분기의 깊이가 깊더라도 완벽하게 탐색하고 다음 분기로 넘어가기 때문에 목표노드가 깊은 .. [알고리즘] 완전탐색 (Exhaustive Search) Exhaustive Search 완전탐색은 무식하게 문제를 풀어나가는 방식이라고 하는데, 필자 생각에는 무식하다는 표현은 어울리지 않는 것 같다. 대부분의 알고리즘 문제는 완전탐색으로 다 풀수 있을 정도로 강력한 방식이다. 물론 그래서 무식하다고 부를 수 있지만 사실 컴퓨팅 성능이 미친듯이 좋으면 어떤알고리즘을 쓰더라도 빠르게 결과를 볼 수 있다. 그래서 무식한 방법이라고 절대 무시하면 안된다. 완전탐색을 문제를 해결하기 위한 모든 경우의 수를 나열하고, 정답을 찾아가는 방법을 의미한다. 완전탐색에는 Brute-Force, Bitmask, Recursive Fuction, Permutation, BFS, DFS 알고리즘이 있다. 완전탐색은 탐색의 방법론을 의미하고 그 안에 다양한 알고리즘들이 있다. Br.. [알고리즘] Queue Queue Queue는 stack과 같이 선형 자료구조 중 하나이며 대표적인 자료구조이다. 선형구조는 '자료가 일렬로 존재하는 구조'를 뜻한다. 예를들면 stack, queue, linked list 등이 있다. Queue에서 꼭 알아야할 개념은 FIFO이다. FIFIO는 First in First out이며 '가장 먼저 들어간 값이 가장 먼저 나간다'라는 의미이다. 즉 우리가 일반적으로 비행기 탑승게이트에서 줄을 서게 되면 먼서 줄선 사람이 먼저 비행기에 탑승할 수 있는 것과 동일하다. 그림을 보면 알 수 있듯이 '앞'에 인는 정보가 추출이 되고 삽입되는 정보는 '뒤'에 쌓이는 것을 알 수 있다. 프로그래밍에서 사용될때는 보통 프린터 버퍼나 영상 버퍼와 같은 '버퍼'를 구현할때도 사용하고, 시뮬레이션을.. [알고리즘] Stack Stack Stack은 선형 자료구조이며 가장 기초적이고 중요한 개념이다. 선형 자료구조란 '자료가 일렬로 존재하는 구조'를 의미한다. 예를들면 stack, queue, linked list 등 이다. stack에서 꼭 알아야 할 것은 바로 LIFO이다. LIFO는 Last in First out이며 '가장 마지막에 들어온 값이 가장 먼저 나간다는 뜻'을 가진다. 즉 데이터가 삽입되는 구멍과 삭제되는 구멍이 동일하다고 이해하면 되겠다. 아래 그림을 보면 좀더 쉽게 이해할 수 있다. 간단하게 예를 들면, 상자 안에 책을 눕혀서 국어책-수학책-영어책 순으로 넣는다면 뺄때는 영어책-수학책-국어책 순으로 빼게 될 것이다. 상자를 부시지 않는 이상 국어책을 빼기 전까지는 수학책 영어책을 빼낼 수 없다 (어떻게서든.. [알고리즘] 해시 테이블 (Hash Table) Hash Table Hash Table는 연관배열 구조를 이용하는 자료구조 중 하나로써 단순하게 생각하면 'key-value'의 구조라고 할 수 있다. 연관배열 자료구조(associative array)란 key와 value가 1:1로 이루어진 구조이다. Hash는 검색과 저장이 빠른 자료구조이다. 파이썬에서는 Dictionary로 구현이되어있고, 자바에서는 java.util 하위에 HashMap, Map으로 정의되어있다. 해시는 값 자체를 Index로 사용하기 때문에 시간복잡도 O(1)로 매우 빠르다. hash table을 사용하여 해결할 수 있는 문제유형은 한 묶음의 데이터에 '중복이 없거나', 데이터가 몇번 발견되는지에 대한 '빈도를 세거나', '순서가 필요하지 않거나', 'key-value 쌍으로.. 이전 1 2 다음